区别:1、ASCII编码是1个字节,而Unicode编码通常是2个字节。2、ASCII是单字节编码,无法用来表示中文;而Unicode可以表示所有语言。3、用Unicode编码比ASCII编码需要多一倍的存储空间。

本教程操作环境:windows7系统、Dell G3电脑。
ASCII编码
Unicode
Unicode和ASCII的区别
UTF8
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:

浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:

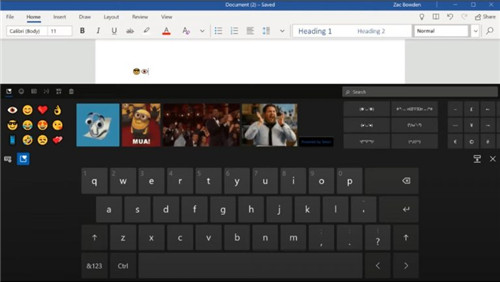 Windows 10带来了新的触摸键
Windows 10带来了新的触摸键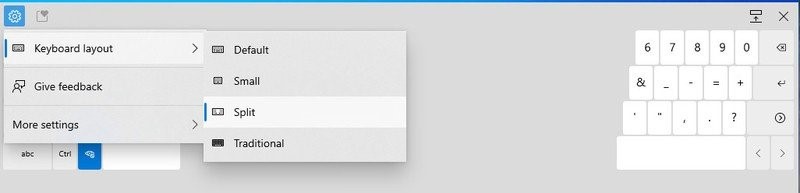 Windows10 Insider内部版本21
Windows10 Insider内部版本21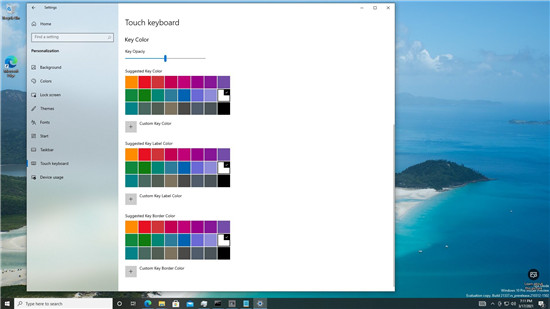 Windows10 Build 21337带来了新
Windows10 Build 21337带来了新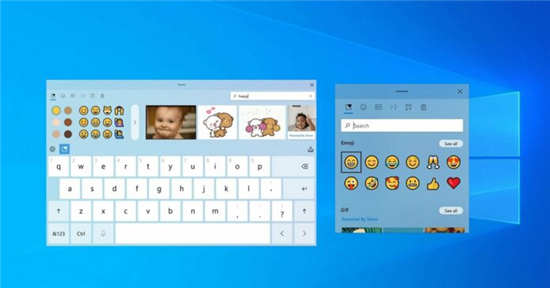 Windows10触控键盘可获取主
Windows10触控键盘可获取主 Windows 10屏幕键盘很快就可
Windows 10屏幕键盘很快就可 Windows 11 的小上下文菜单按钮会让人们感
Windows 11 的小上下文菜单按钮会让人们感 用户想要Win11中的更多开始菜单设置:包括
用户想要Win11中的更多开始菜单设置:包括 交叉线网线的顺序是怎么排的_标准交叉网
交叉线网线的顺序是怎么排的_标准交叉网 Microsoft Office 2021:为应用于Windows 11重新设
Microsoft Office 2021:为应用于Windows 11重新设 泄漏的Microsoft键盘显示Windows 10表情符号的Windows 10带来了新的触摸键盘体验,而且非
泄漏的Microsoft键盘显示Windows 10表情符号的Windows 10带来了新的触摸键盘体验,而且非 屏幕键盘上的Windows 10X默认显示为隐藏在
屏幕键盘上的Windows 10X默认显示为隐藏在
它已经传言了一段时间,该元素现在已经推迟的Windows 10X操作系......
阅读
Windows 11 的小上下文菜单按钮会让人们感
总体而言,Windows 11是Windows的完美新版本。但它有一些严重的烦......
阅读
用户想要Win11中的更多开始菜单设置:包括
用户想要Win11中的更多开始菜单设置:包括一个调整整个开始菜单......
阅读
交叉线网线的顺序是怎么排的_标准交叉网
交叉线网线的顺序是怎么排的_标准交叉网线制作方法(网线水晶......
阅读
Microsoft Office 2021:为应用于Windows 11重新设
Microsoft Office2021:为应用于Windows11重新设计的界面 bull;新的和改......
阅读阅读
阅读
阅读
阅读
阅读

阅读
阅读
阅读

阅读
阅读